This project was completed for LIS 664, Programming for Cultural Heritage, and fulfills the Communication requirement of the e-portfolio. Hidden Worlds DB, visible at this link: http://hiddenworldsdb.org/ is a database of information about a group of science fiction authors that used pseudonyms using several digital tools and allows for research to be conducted on this group in an accessible format. As a linked data project, Hidden Worlds DB makes more information available in the semantic web and connects existing informational resources on the internet, expanding the scope of researchers. The project was created using traditional research methods and by creating new digital tools using python and drupal.
My Role: I was the head of the programming side of this project, as well as the originator of the idea and concept, and helped with the project planning and management. I also created the front-end visualizations for the site.
Description and Methods:
I read a lot of sci fi and fantasy books growing up (and still do, I am not ashamed), which meant I read a lot of books by mostly male (also white) authors. Or so I thought. Several years ago, when packing my things up for a final move out of my parent’s house I found an old hardcover book: Up the Walls of the World by James Tiptree, Jr. I remembered reading it, and how profoundly strange many aspects of it were, so I put it in a box, thinking I might revisit it sometime. A year later I was bored and picked it up off the shelf and started reading. Though the book is dated in many ways, there are some interesting and weird ideas in it and I wanted to know more about the author. The book had never had a dust jacket (I got it from my uncle who hoards pulp sci fi mass markets and does not have an archival view towards his numerous books) so I looked up Tiptree on the internet, and discovered that he was actually Alice B. Sheldon, a mid-20th century writer who adopted a masculine pen name so her work would be picked up by the overwhelmingly male-dominated sci fi publishing world. Sheldon is in fact, a bit famous within the sic fi world now, she has an annual award named for her celebrating the best sci fi novel of the year that addresses gender, but the pressures that caused her to hide her gender still exist, according to a Dec. 6, 2012 Wall Street Journal article entitled “Why Women Writers Still Take Men’s Names” which mostly focuses on genre writers (in particular sci fi and fantasy) and how men are less likely to buy books written by women. It’s sad to me that genres I love for their imagination are still driven by a blinkered and unimaginative view of who can write what. This project seeks to show how widespread this practice was, and in some ways still is, and showcase the work of writers who were forced to hide their true selves.
Data Sources
The data for this project came from three main sources: FeministSF.org, the Internet Speculative Fiction Database (ISFDB), and dbPedia. FeministSF.org keeps a list of female and female-identified authors on their site, including the pseudonyms those authors wrote under. There are other, similar lists available online, but this is the most comprehensive one so far. The list is in html format and will need to be extracted from the site. The list is offered under a creative commons license that requires attribution, bans commercial use, allows remixing, and requires users to share-alike. There are some inconsistencies in the phrasing of the list: sometimes the pseudonym is listed first and the real name second, and sometimes it is the other way around.
Dbpedia provided initial biographical and editorial information on the authors, using the SPARQL endpoint to query the database for data about the authors life and publishing career. Queries will return data on birth and death dates, publishers, books, alternate names or pseudonyms, themes, and other data. Dbpedia has a lot of possible information, but might lack information on more obscure authors and books. The data is made available under a creative commons license that requires attribution, allows remixing, and requires users to share-alike.
The ISFDB provided data about books and authors through two portals. The main site also has a search function for author’s names and returns a list of books in html. The also database provides information about books through an API that takes a book’s ISBN as an argument and returns an XML structure containing the metadata for that particular publication. The ISFDB records of books is more complete than dbpedia’s and can be used to supplement the listing of author’s publications received form dbpedia. The main site search will provide a listing of authors’ publications, including ISBN numbers. The API will provide a great deal of metadata about the books, such as: publisher, editor, cover artist, list price, series, page count, and publication year. A python script can access the data from the API programmatically, and hopefully a screenscraper or use of a service like uriburner can extract the data from the main site.
Using the list from FeministSF, which lists female sci fi and fantasy authors along with any pseudonyms used, and pulling all the names out that have the word ‘pseudonym’ near them would give me a starting place (after eliminating authors with non-masculine pseudonyms). I would also include pseudonyms that occlude the authors gender (the most recent famous example being J.K. Rowling). Then running those names through dbPedia to see if they have pages there and pulling out any pertinent data: DOB, country, awards, list of works (if possible), and working relationships (also if possible).
Python scripts were written to scrape the data from dbpedia and the ISFDB en masse. The scripts are available on the Hidden Worlds DB site.
Data Transformation
The data can be broken down into categories: Author, Book, Publisher, and Editor. Data that comes from screenscraping will be HTML or text, depending on whether the screenscraper preformed any transformations. Dbpedia data can come in JSON, XML or as an XSLT table, and ISFDB provides data in the XML format and as an SQL database. Some modification of the HTML, text and XSLT data were done in OpenRefine or Excel to clean it up and standardize the formating. Remaining modifications were done in OpenRefine or a text parser to convert the data into RDF.
The URIs for the authors came from the Virtual International Authority File (VIAF) because of it’s wide scope and reliability. Any author that lacks an URI in VIAF received one from dbpedia or ISFDB. Books’ URIs will come from the ISFDB because of its focus on identifying obscure works. Publishers and Editors will receive URIs from VIAF or dbpedia. We took data from several different sources and merging them into several tables using the Name of the author as the common linkage.
Vocabularies
Several vocabularies were used for this project: dcterms, owl, foaf, and a singular on of our own creation. The one of our own creation is a refining of an existing ontology property that exists in OWL: pseudonym. This term is defined as such:
Ontology datatype property (help)
rdfs:label (en)
pseudonym
rdfs:label (nl)
pseudoniem
rdfs:label (de)
Pseudonym
rdfs:domain
Person
rdfs:range
xsd:string
The new property will be a subproperty of the existing property with the further definition of an intent to mask the gender of the subject. For now, the property will be named ‘gendermask’ and will be defined on the site of this project.
Ontology datatype property (help)
rdfs:label (en)
gendermask
rdfs:domain
Person
rdfs:range
xsd:string
rdfs:subPropertyOf
pseudonym
Additional terms that will be used:
rdfs: label – To provide human readable titles for Authors, Books, Editors and Publishers
dcterms:creator – To identify the creator of a work
dcterms:editor – To identify the editor of a work
dcterms:publisher – To identify the publisher of a work
dcterms:ISBN – to identify the ISBN of a work
owl:birthDate – to identify the birth date of an author
owl:deathDate – to identify the death date (if any) of an author
owl:birthPlace – to Identify the Birth place of an author
owl:sameAs – To link resources that are the same. This will be particularly useful to link books and publishers to both the actual name and pseudonym of the authors.
foaf:primaryTopic – To identify the homepage or other external information page of the author
Requirement: Communication
The product of this project is a website that offers several entry points to the data collected, and different ways to fulfill the Communication requirement. The resulting data was transformed into triples in turtle either using a python parser or Open Refine and the author names are related to the pseudonyms, and both of those will be related to the other objects: editors, books, publishers, locations. Books are related to publishers and authors.
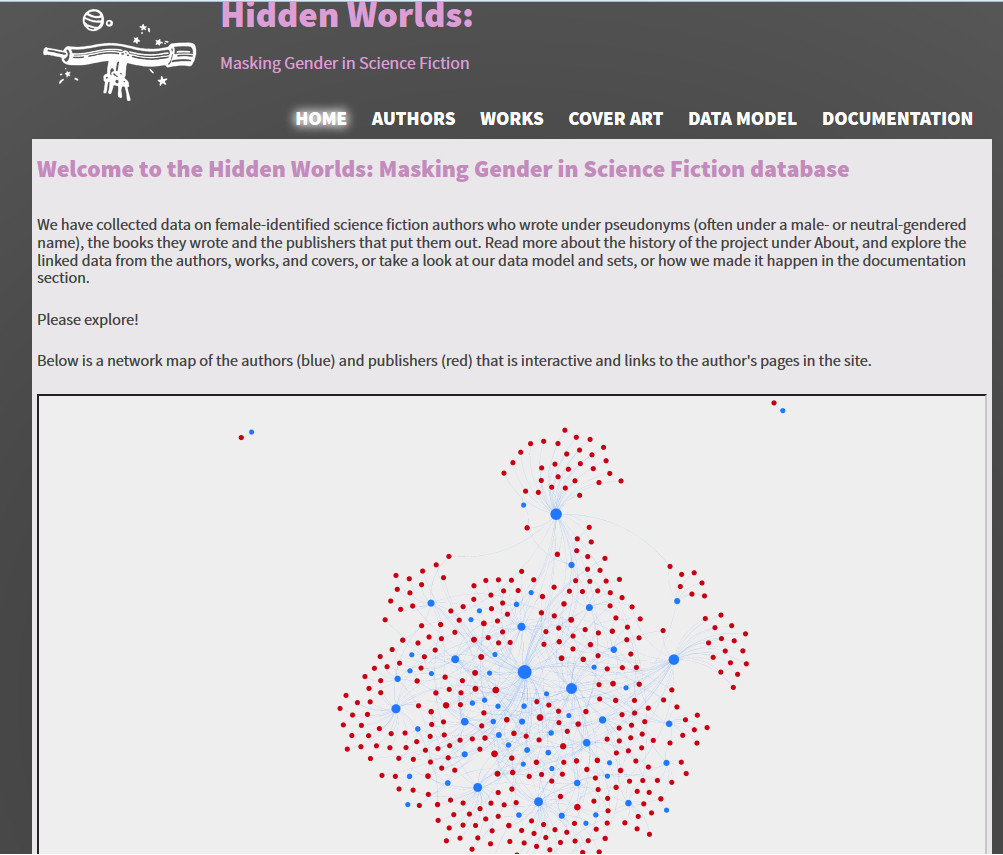
The front end of the site has a graphical representation of the authors, as floating nodes linked to publishers. The node displays information on the author including pseudonym and perhaps a picture. Clicking on the node takes the user to a static page displaying the data about the author with links to pages for books, publishers and editors. Each author has a page with biographical information and works. There is a searchable database of the authors and works as well as a gallery of book covers. Users can search or browse this section to discover connections between authors, publishers and works, and learn general information about the authors.
Additionally, all of the data for the project is available as triples and in turtle for use with linked data projects.
